
{kind=link}
Veeam is introducing another new feature called Scale-Out Backup repository. A global single pool which contains all your existing backup repositories. This feature will be is present in Veeam Availability Suite v9. Check out my latest post Veeam Backup and Replication 9 Released!
How does it work? In fact, you'll be able to gather all your existing backup repositories, add a new ones as-you-go, to a global pool which is then presented as a backup target.
So it's kind of abstraction being made so each backup job is configured equally, not like today where you have perhaps many backup targets and your backup jobs are grouped together to create backups at those different backup targets.
In v8 when specify backup target, you do it “per device”. This is traditionally working well, until you're running out of space at one of those backup targets. You have to usually add a new storage, relocate existing backup files to the new storage, and then only you can continue to run your backups. So that's a principal advantage. It's the global pool which “distributes” those files across all those individual backup targets when running backup jobs, so the space is used evenly.
Another function that the v9 will leverage is the different performance of each of those extends. Each of those individual backup targets has possibly a different performance. Some storage might be slower than other. SATA disks vs SAS or even SSD….You see, this can be (and surely it is! ) very variable. Veeam is able to leverage those different performance levels and place the Veeam backup files the best possible way in order to get the best performance from the pool.
Quote from Luca's post:
Every type of backup storage is different, and scale-out backup repository is designed with this in mind. For each extent, you will be able to assign it a “role”: with just a few mouse clicks, you will define if a repository of the group will accept full backups, incremental backups, or both.
By assigning incremental backups to one extent and fulls to the other, when a transform happens one I/O (read) out of the two I/O operations is now performed by the repository holding the incrementals, while only one single (write) I/O is left to the one holding the full backups.
This is kind of cool (very cool I would say), as by creating those policies you'll be able to auto-optimize the whole back end scaleout pool in order to obtain the best possible performance for your backups. This is adaptable on each client's storage, is configurable for each of those individual client's environments.
The only image I got so far is this one….
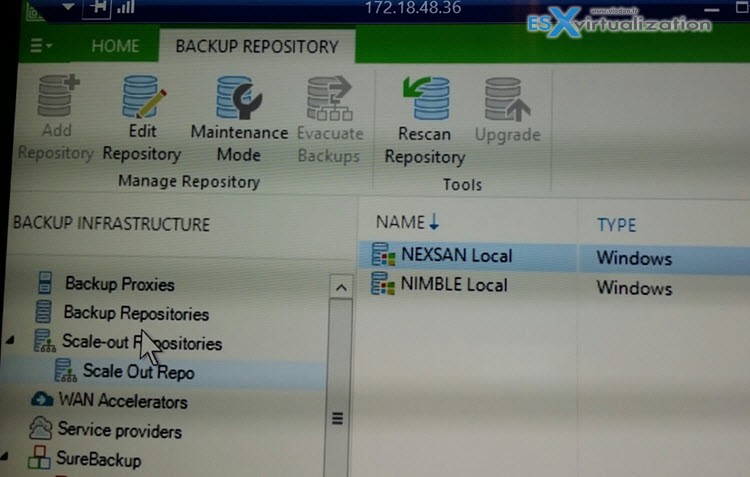
Veeam v9 shall be out Q4 2015. Stay tuned for more… -:)
If you haven't checked out the Free Veeam Endpoint Backup for Linux announce, you definitely should.
Disclaimer: I’ve been invited to this event by Veeam, due to the Veeam Vanguard program benefits, and they will paid for accommodation and travels, but I’m not compensated for my time and I’m not obliged to blog. Furthermore, the content is not reviewed, approved or published by any other person than me.