
LUN and HBA Queue Depth on ESX(i) Hosts.
This is a guest post by Andy Grant.
This article is in response to the post More Questions About Queues: LUN and HBA Queue Depth on ESX(i) Hosts. I previously posed a few questions about the behavior of vSphere’s SIOC and (LUN) Adaptive Queue Depth algorithm and have a few observations to report.
While I don’t have a FC or iSCSI SAN in my lab, direct attached storage should behave in the same manner, albeit with different default queue depths. For this test I setup 3 WinXP VM’s running IOMeter v1.1-RC1 on a single OCZ Vertex 2 SSD attached to an HP Smart Array P410 controller (no RAID, 512MB BBWC). My host is running vSphere 4.1U1 build 381511.
A review of the questions I asked.
- SIOC dynamically changes LUN queue depth (DQLEN) depending on load, how does this effect Disk.SchedNumReqOutstanding?
- The adaptive queue depth algorithm dynamically changes DQLEN, how does this effect Disk.SchedNumReqOutstanding?
- Many consider VAAI to be the god-send for increasing VM per datastore ratios with hardware accelerated fine-grained block-level SCSI locking, so will the array per-LUN queue depth be the next bottlenext? See the Scalable Storage Performance page 5 for more on this.
SIOC dynamically changes LUN queue depth (DQLEN) depending on load, how does this effect Disk.SchedNumReqOutstanding?
Before I start to take a look at SIOC, I ran into the following statement and wanted to preemptively clear up the murky wording.
Troubleshooting Storage I/O Control
“SIOC is only supported on Fibre Channel and iSCSI connected storage”
I thought it would be useful to denote that while it may only be supported on FC & iSCSI storage, it does enable and work on the direct attached storage in my lab.
Let us compare the same IOMeter load with SIOC disabled and enabled:
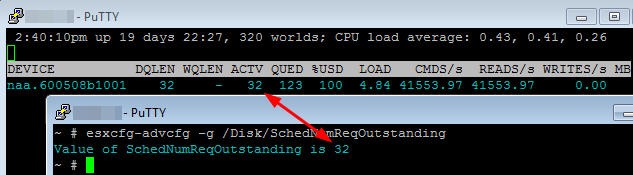
SIOC DISABLED
SIOC ENABLED
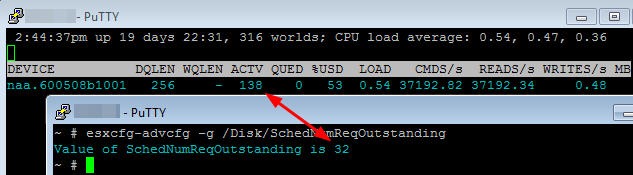
The Answer: SIOC ignores the Disk.SchedNumReqOutstanding parameter.
As you can see, with SIOC disabled and a full load, the LUN queue depth (DQLEN) mirrors Disk.SchedNumReqOutstanding. Disk.SchedNumReqOutstanding is clearly impacting performance of the high performance SSD. Since Disk.SchedNumReqOutstanding is a global parameter, increasing the value may benefit the SSD-backed LUN but negatively impact other lower performance LUNs. With SIOC enabled, it ignores Disk.SchedNumReqOutstanding and increases the DQLEN to match the performance of the LUN.
This result surprised me. Reading https://www.vmware.com/files/pdf/techpaper/vsp_41_perf_SIOC.pdf makes you believe that SIOC is only useful for throttling VM’s based on disk shares and slots. This is clearly not the case and based on this result I have new respect for the benefit of SIOC. The argument for Enterprise Plus versus Enterprise just got a little more interesting.
The adaptive queue depth algorithm dynamically changes DQLEN, how does this effect Disk.SchedNumReqOutstanding?
I tested this with SIOC disabled.
Take a look at the DQLEN with no load on the LUN, as you can see it is sitting at 512 (being a direct attached LUN).
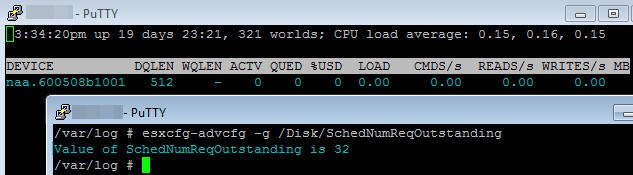
When a load is applied the DQLEN then drops to my Disk.SchedNumReqOutstanding.
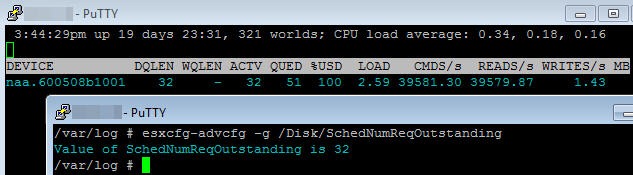
And if I change Disk.SchedNumReqOutstanding then DQLEN follows suit.
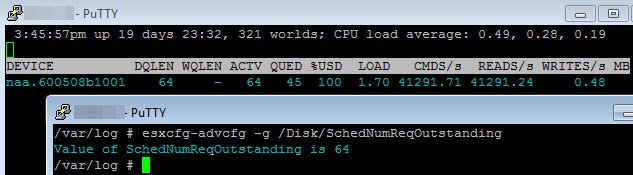
Now according to the KB article
“This algorithm can be activated by changing the values of the QFullSampleSize and QFullThreshold parameters. When the number of QUEUE FULL or BUSY conditions reaches the QFullSampleSize value, the LUN queue depth reduces to half of the original value. When the number of good status conditions received reaches the QFullThreshold value, the LUN queue depth increases one at a time.”
I did test adjusting the values but could not find any change in behavior, therefore I am assuming that the algorithm is enabled by default in vSphere 4.1U1 since DQLEN starts at 512 and drops as load is applied. I would be interested to hear your experiences if they are different than mine.
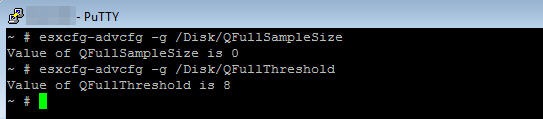
The Answer: the adaptive queue depth algorithm uses Disk.SchedNumReqOutstanding as the lowest bound threshold for DQLEN.
Many consider VAAI to be the god-send for increasing VM per datastore ratios with hardware accelerated fine-grained block-level SCSI locking, so will the array per-LUN queue depth be the next bottlenext?
See the Scalable Storage Performance page 5 for more on this.
The Answer: It depends ![]() Some arrays have per-LUN queue limits, and for others it may not be an issue. Ultimately a dynamic solution such as SIOC is the answer here.
Some arrays have per-LUN queue limits, and for others it may not be an issue. Ultimately a dynamic solution such as SIOC is the answer here.
Further Discussion.
The results from the SIOC testing really drove home an interesting fact, lowering Disk.SchedNumReqOutstanding can potentially negatively impact your VM disk latency performance. While it is difficult to capture an identical IOPS value between the comparison since they bounce around quite a bit, they were mostly the same. While achieving similar IOPS, lowering LUN queue depth can increased latencies due to queuing. I think this has a greater wide-spread impact than you might believe at first glance.
Consider your cluster size, the number of hosts in your cluster. There are VMware KB articles indicating the more hosts you have accessing a shared LUN, the lower the HBA queue depth should be. A really great example of this is documented in Hitachi’s VSP Best Practices Guide https://www.hds.com/assets/pdf/optimizing-the-hitachi-virtual-storage-platform-best-practices-guide.pdf on page 35. Hitachi recommends lowering your HBA queue depth based on the number of back-end disks, number of LUNs and HBA’s accessing FED (Front End Director ports).
According to VMware KB
Changing the Queue Depth for QLogic and Emulex HBAs
“The recommendation is to set both Disk.SchedNumReqOutstanding and the adapter queue depth to the same value.”
The side effect of lowering your HBA queue depth (AQLEN) is that you should lower your Disk.SchedNumReqOutstanding. And based on Hitachi’s equation, the more hosts & HBA’s in your cluster the lower your HBA queue depth, and by VMware’s recommendation, Disk.SchedNumReqOutstanding should be.
Thankfully, lowering the number of LUN’s we have may offset this effect, and that is where VAAI helps us by allowing fewer larger LUN’s.
Recommendation: Be mindful of your cluster sizing, and if you have the benefit of using fewer, larger, more heavily populated LUN’s using VAAI, be sure that you do not exceed the LUN or FED queue limits imposed by your storage array. Exceeding these limits without SIOC may negatively impact VM disk latency.
Update: iSCSI testing here https://www.vladan.fr/sioc-and-adaptive-queue-depth-testing-on-iscsi-luns/
Hi, for the Disk.SchedNumReqOutstanding and DQLEN I found something in the old VMware whitepaper “scalable storage performance”. It says “Also make sure to set the Disk.SchedNumReqOutstanding parameter to the same value as the queue depth. If this parameter is given a higher value than the queue depth, it is still capped at the queue depth. However, if this parameter is given a lower value than the queue depth, only that many outstanding commands are issued from the ESX kernel to the LUN from all virtual machines. The Disk.SchedNumReqOutstanding setting has no effect when there is only one virtual machine issuing I/O to the LUN. “
I just realized that I could have got wrong with a detail. The queue depth mentioned is actually referring to the QD per LUN configured on HBA. Please ignore my previous post.
And thank you for all the great posts. Most helpful!