
There is new PDF from VMware detailing best practices for VMware VSAN. The title says it all – VMware VSAN Stretched Cluster Performance and Best Practices. It does targets the latest VMware VSAN 6.1 where stretched cluster feature was introduced. A possibility to have a full site (with VSAN) failure. You'll see some detailed tests which looks at the overhead of synronous replication of data across two geographical sites. Those tests are compared with traditional single cluster VSAN deployment scenario.
The paper was written by Amitabha Banerjee (Staff Engineer in the I/O Performance Engineering group at VMware) and Zach Shen who is a Member of Technical Staff in the I/O Performance Engineering group at VMware.
A write latency in stretched cluster scenario has to deal with network latency as the data has to travel through the inter-site links. The result shows some degradation of performance, which is understandable considering that with more inter-site latency those writes takes more time to proceed on both sides simultaneously. But the most important feature of VSAN – The ability to maintain data availability even under the impact of complete site failure, shows the robustness of the solution while keeping the setup relatively simple.
They tested disk failure:
At around the time of 80 minutes, a single HDD was failed on one of the Virtual SAN nodes that had 4 HDDs, and the HDD was removed from the Virtual SAN data store. The failed HDD may have multiple objects on it. This triggered the recovery operation in which Virtual SAN recreated replicas of all the objects on the failed disk. Recovery traffic lasted for a duration of 54 minutes, the average recovery traffic was 15 megabytes per second, and the peak recovery traffic was 33 megabytes per second.
And also complete site failure:
After the workload performance achieved steady state, an entire site (Site 1) of four nodes was turned down. This affected four virtual machines on the site that had been powered off. vSphere HA restarted the virtual machines on the other site (Site 2) and distributed one affected virtual machine on each node of the remote site. The site outage did not affect data availability because a copy of all the data of Site 1 existed on Site 2. Thus, the affected virtual machines were automatically restarted by vSphere HA without any issues
Servers config:
- Dual-socket Intel® Xeon® CPU E5-2670 v2 @ 2.50GHz system with 40 Hyper-Threaded (HT) cores
- 256GB DDR3 RAM @ 1866MHz
- One LSI / Symbios Logic MegaRAID SAS Fusion Controller with driver version: 6.603.55.00.1vmw, build: 4852043
- One 400GB Intel S3700 SSDs
- Four 900GB Western Digital WD9001BKHG-02D22 HDDs
- One dual-port Intel 10GbE NIC (82599EB, Fibre Optic connector)
- One quad-port Broadcom 1GbE NIC (BCM5720)
Image (courtesy of VMware) from the paper showing the latency vs IOPS per node:
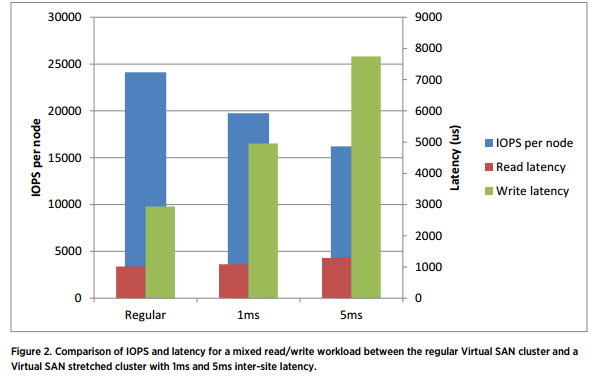
Impact of inter-site latency:
The experiments show that with DVD Store, the Virtual SAN stretched cluster can sustain the overhead of 5ms latency without much impact to the benchmark performance. However, a 5ms inter-site latency does impact the write latency manifold when compared to a regular Virtual SAN deployment. It is recommended to limit inter-site latency to the order of 1ms, unless customer applications can tolerate high write latency.
Get the paper from this resource page here