
Today's VCP6 topic is following: VCP6-DCV Objective 7.5 – Troubleshoot HA and DRS Configurations and Fault Tolerance. A large topic, which is difficult to fit into single post.
The VCP6-DCV certification exam validates that you have the skills required to successfully install, deploy, scale and manage VMware vSphere 6 environments.
Check the VCP6-DCV Study Guide [Unofficial] page on my blog for all topics required to pass the exam. Stay tuned for the PDF version …. Check also other How-to articles, videos, and news concerning vSphere 6 – dedicated vSphere 6 page.
vSphere Knowledge
- Identify HA/DRS and vMotion requirements
- Verify vMotion/Storage vMotion configuration
- Verify HA network configuration
- Verify HA/DRS cluster configuration
- Troubleshoot HA capacity issues
- Troubleshoot HA redundancy issues
- Interpret the DRS Resource Distribution Graph and Target/Current Host Load Deviation
- Troubleshoot DRS load imbalance issues
- Troubleshoot vMotion/Storage vMotion migration issues
- Interpret vMotion Resource Maps
- Identify the root cause of a DRS/HA cluster or migration issue based on troubleshooting information
- Verify Fault Tolerance configuration
- Identify Fault Tolerance requirements
—————————————————————————————————–
Identify HA/DRS and vMotion requirements
vSphere HA is very easy to set up and manage and is the simplest high-availability solution available for protecting virtual workloads.
HA Requirements:
- Redundant Management Network – Verify that you are using redundant management network connections for vSphere HA. For information about setting up network redundancy, see “Best Practices for Networking.”
- Proper Licensing – vSphere Essentials Plus and higher licensing. Essentials (only) won't do the job…
- Minimum 2 hosts in a cluster – HA needs 2 hosts to be able to initiate failover.
- Static IP config – Host which participate in HA/DRS clusters has to be configured with static IP address.
- Shared Storage – VMs must run on shared storage
- Access All hosts to VM neworks and datastores – All Hosts shall be able to reach the VM's networks and datastores.
- VMware tools on VMs – All VMs has to have VMware tools in stalled in order to be able to activate VM Monitoring
- Configure Two Shared Datastores at least – to have redundancy for vSphere HA datastore hearbeating.
- ipv6 and ipv4 are supported – vSphere HA supports both IPv4 and IPv6. See “Other vSphere HA Interoperability Issues,” on page 31 for considerations when using IPv6.
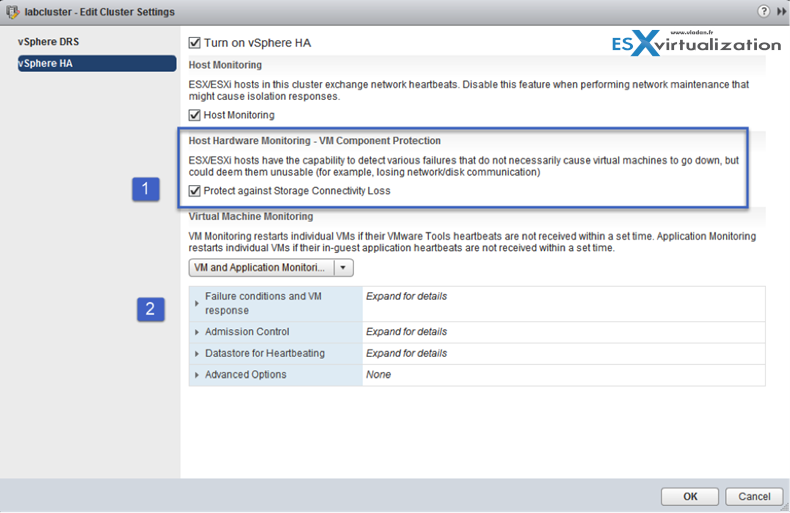
- Enable APD Timeout – If you want to use VM Component Protection, hosts must have the All Paths Down (APD) Timeout feature enabled.
- Wants VMCP with HA? – To use VM Component Protection, clusters must contain ESXi 6.0 hosts or later.
DRS Requirements:
vCenter server resource management p.63
- Shared storage – SAN/NAS, VSAN… any supported shared storage.
- Configure all managed hosts to use shared VMFS volumes. Place the disks of all virtual machines on VMFS volumes that are accessible by source and destination hosts. Make sure that the VMFS volume is sufficiently large to store all virtual disks for your virtual machines and also make sure that all VMFS volumes on source and destination hosts use volume names, and all virtual machines use those volume names for specifying the virtual disks.
- CPU Requirements – use EVC to help you out with different hardware in your cluster.
vMotion Requirements:
- Gigabit ethernet for vMotion is a bare minimum – make sure you comply with that
- No MSCS support – Microsoft Cluster service (MSCS) isn't supported.
- VMs with CDROM Unattached – Cannot vMotion a VM that is backed by a device that isn't accessible to the target host. I.E. A CDROM connected to local storage on a host. You must disconnect these devices first. USB is supported as long as the device is enabled for vMotion
- For VMs with USB – must enable all USB devices that are connected to the virtual machine from a host for vMotion. If one or more devices are not enabled for vMotion, migration
will fail. - TCP port 8000 – incoming and outgoing firewall port for ESXi hosts, this is a required port for vMotion.
sVMOtion Requirements:
- Only virtual compatibility mode . With RDMs in virtual compatibility mode, the raw disk will be migrated to either a thin provisioned or thick vmdk. You might check this KB for further details as there are 3 possibilities Migrating virtual machines with Raw Device Mappings (RDMs)
Verify vMotion/Storage vMotion configuration
- Check the vmkernel network interfaces for the correct network config.
- Make sure that the EVC in the cluster is configured (if needed) and tested prior enabling DRS.
- Make sure that all hosts within cluster can reach the shared storage and no VMs are left on local storage somewhere….
Verify HA network configuration
Check this section at the vSphere Availability Guide p.29 and p.39
- When you change the networking configuration on the ESXi hosts themselves, for example, adding port groups, or removing vSwitches, suspend Host Monitoring. After you have made the networking configuration changes, you must reconfigure vSphere HA on all hosts in the cluster, which causes the network information to be reinspected. Then re-enable Host Monitoring.

On ESXi hosts in the cluster, vSphere HA communications, by default, travel over VMkernel networks. With an ESXi host, if you wish to use a network other than the one vCenter Server uses to communicate with the host for vSphere HA, you must explicitly enable the Management traffic check-box.
Der, Die, Das! Isolation Address
das.isolationaddress
By default, the network isolation address is the default gateway for the host. Only one default gateway is specified, regardless of how many management networks have been defined. You should use the das.isolationaddress[…] advanced option to add isolation addresses for additional networks.
This address is pinged only when heartbeats are not received from any other host in the cluster. If not specified, the default gateway of the management network is used. This default gateway has to be a reliable address that is available, so that the host can determine if it is isolated from the network. You can specify multiple isolation addresses (up to 10) for the cluster:
das.isolationaddressX, where X = 0-9.
Typically you should specify one per management network. Specifying too many addresses makes isolation detection take too long.
Check p.37 for all advanced options.
Verify HA/DRS cluster configuration
You can check the cluster summary through vSphere client or vSphere web client.
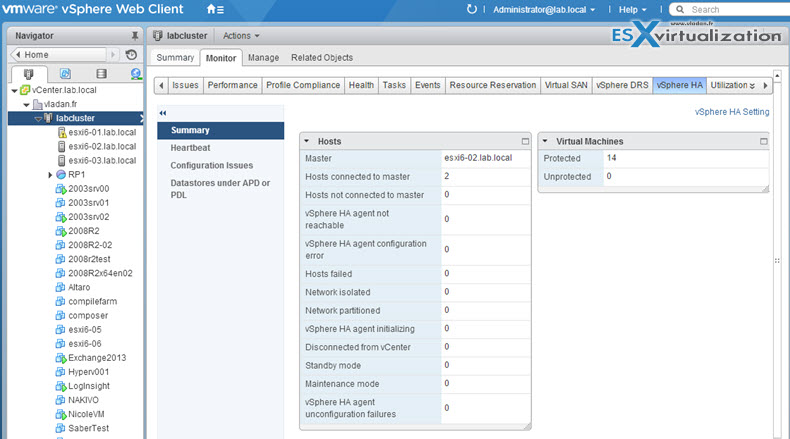
vSphere client…
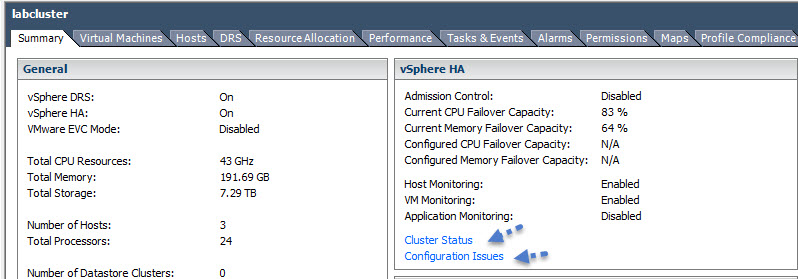
Troubleshoot HA capacity issues
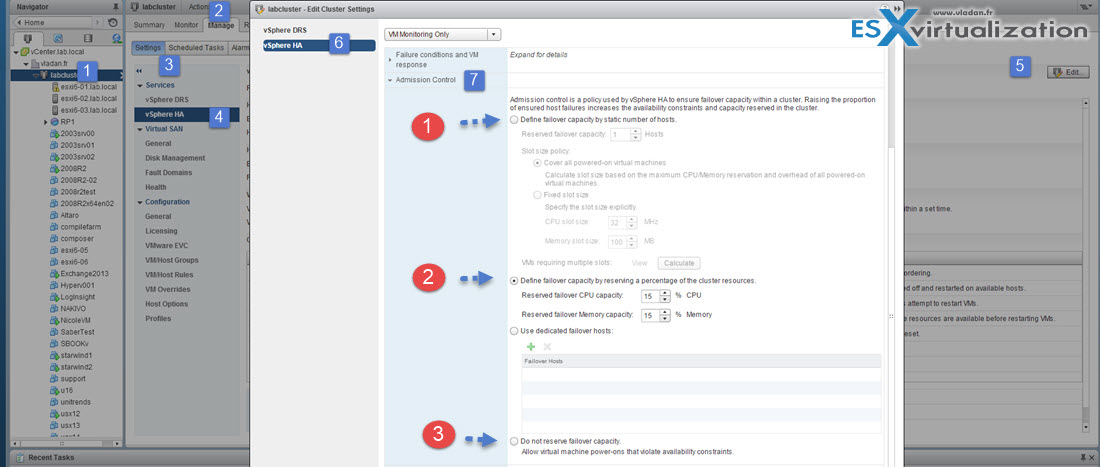
As you know the 3 possible HA admission config policies you must know are:
- Host Failures Cluster Tolerates – With the Host Failures Cluster Tolerates admission control policy, VMware HA ensures that a specified number of hosts can fail and sufficient resources remain in the cluster to fail over all the virtual machines from those hosts
- Percentage of Cluster Resources – You can configure VMware HA to perform admission control by reserving a specific percentage of cluster resources for recovery from host failures. With the Percentage of Cluster Resources Reserved admission control policy, VMware HA ensures that a specified percentage of aggregate cluster resources is reserved for failover.
- Specify a Failover Host – when a host fails, VMware HA attempts to restart its virtual machines on a specified failover host. If this is not possible, for example the failover host itself has failed or it has insufficient resources, then VMware HA attempts to restart those virtual machines on other hosts in the cluster.
The three HA admission configuration policies…
What can go wrong? Hosts disconnected, unconfigured (right click > reconfigure for HA). Also when (if) setting “specify failover host” policy, than you might end up with some VMs non restarted if several hosts fails, as you did not set enough hosts for failover. I usually use “percentage of cluster resources” or “host failures cluster tolerates” policies.
If your cluster contains any virtual machines that have much larger reservations than the others, they will distort slot size calculation. To avoid this, you can specify an upper bound for the CPU or memory component of the slot size by using the das.slotcpuinmhz or das.slotmeminmb advanced attributes, respectively.
Slot size is comprised of two components, CPU and memory.
- vSphere HA calculates the CPU component by obtaining the CPU reservation of each powered-on virtual machine and selecting the largest value. If you have not specified a CPU reservation for a virtual machine, it is assigned a default value of 32MHz. You can change this value by using the das.vmcpuminmhz advanced attribute.)
- vSphere HA calculates the memory component by obtaining the memory reservation, plus memory overhead, of each powered-on virtual machine and selecting the largest value. There is no default value for the memory reservation.
If large VMs present in the cluster than you might want to use “percentage of cluster resources” admission policy as you won't need to deal with slot sizes.
Troubleshoot HA redundancy issues
NIC teaming is the answer. Redundancy, redundancy…. Use 2 or more pNICs in a team to provide failover possibility. If possible use separate physical switches to provide redundancy.
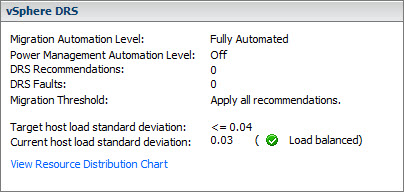
Interpret the DRS Resource Distribution Graph and Target/Current Host Load Deviation
Even if VMware is pushing the web client, I feel that the C# client shows more details when flying over with a mouse on a chart to display the memory utilization of a host within cluster, you can actually see an individual VM, how such a VM consumes memory on that particular host…
You can access the charts (in vSphere client) from the summary tab when selecting your cluster on the left hand side first. Click the “View resource distribution chart” link, as on the image below….
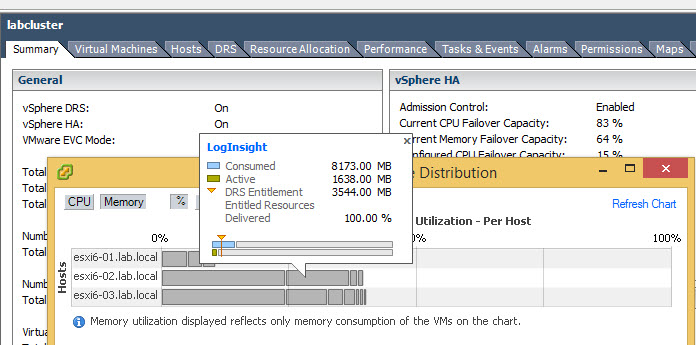
This is not the case of vSphere Web client….
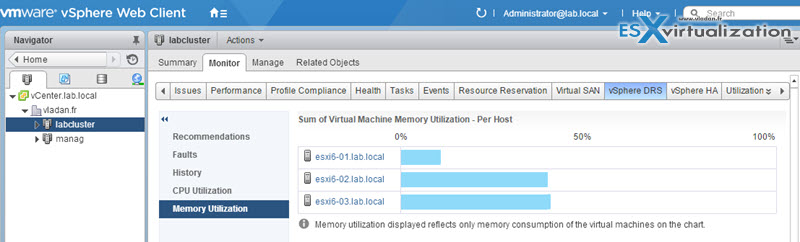
The DRS Resource Distribution chart displays CPU or Memory metrics for each of the hosts in the cluster. YOu can switch from percentage to mebabytes (for memory) resp from percentage to megaherty (for CPU).
DRS cluster is load balanced when each of its hosts’ level of consumed resources is equivalent to the others. When they aren’t, the cluster is considered to be imbalanced and VMs must be relocated to restore the balance.
Troubleshoot DRS load imbalance issues
Imbalanced load issues can happens if:
- Host is in maintenance mode
- VM-host affinity/anti-affinity rules being used
- VM-VM affinity rules being used
A cluster might become unbalanced because of uneven resource demands from virtual machines and unequal capacities of hosts.
- The migration threshold is too high – A higher threshold makes the cluster a more likely candidate for load imbalance.
- Affinity/Anti-Affinity Rules – VM/VM or VM/Host DRS rules prevent virtual machines from being moved.
- Disabled DRS – DRS is disabled for some VMs…
- A device is mounted to one or more virtual machines preventing DRS from moving the virtual machine in order to balance the load.
- Virtual machines are not compatible with the hosts to which DRS would move them. That is, at least one of the hosts in the cluster is incompatible for the virtual machines that would be migrated. For example, if host A's CPU is not vMotion-compatible with host B's CPU, then host A becomes incompatible for powered-on virtual machines running on host B.
- It would be more detrimental for the virtual machine's performance to move it than for it to run where it is currently located. This may occur when loads are unstable or the migration cost is high compared to the benefit gained from moving the virtual machine.
- Unconfigured/disabled vMotion – vMotion is not enabled or set up for the hosts in the cluster.
Troubleshoot vMotion/Storage vMotion migration issues
First, check requirements for vMotion/sVMotion.
- VMware tools status – Make sure that VMtools installaiton is not “stuck” in a VM…as during installation of VMware tools it's not possible to do a VMotion of such a VM due to hearbeats.
- Source destination datastores are available – make sure that this apply…
- Licensing – sVMotion requires vSphere “standard”licensing…
- If RDM is used in physical compatibility mode – no snapshoting of VMs… Virtual machine snapshots are available for RDMs with virtual compatibility mode only. Physical Compatibility Mode – VMkernel passes all SCSI commands to the device, with one exception: the REPORT LUNs command is virtualized so that the VMkernel can isolate the LUN to the owning virtual machine. If not, all physical characteristics of the underlying hardware are exposed. It does allows the guest operating system to access the hardware directly. VM with physical compatibility RDM has limits like that you cannot clone such a VM or turn it into a template. Also sVMotion or cold migration is not possible.
A quick quote from VMware blog post, which is new (note that sVMotion do not work with such a disks):
In vSphere 6.0, you can configure two or more VMs running Windows Server Failover Clustering (or MSCS for pre-Windows 2012 OSes), using common, shared virtual disks (RDM) among them AND still be able to successfully vMotion any of the clustered nodes without inducing failure in WSFC or the clustered application. What's the big-deal about that? Well, it is the first time VMware has ever officially supported such configuration without any third-party solution, formal exception, or a number of caveats. Simply put, this is now an official, out-of-the-box feature that does not have any exception or special requirements other than the following:
- The VMs must be in “Hardware 11” compatibility mode – which means that you are either creating and running the VMs on ESXi 6.0 hosts, or you have converted your old template to Hardware 11 and deployed it on ESXi 6.0
- The disks must be connected to virtual SCSI controllers that have been configured for “Physical” SCSI Bus Sharing mode
- And the disk type *MUST* be of the “Raw Device Mapping” type.
Interpret vMotion Resource Maps
A vCenter map is a visual representation of your vCenter Server topology. Maps show the relationships between the virtual and physical resources available to vCenter Server.
Maps are available only when the vSphere Client is connected to a vCenter Server system.
The maps can help you determine such things as which clusters or hosts are most densely populated, which networks are most critical, and which storage devices are being utilized. vCenter Server provides the following map views.
- Virtual Machine Resources – Displays virtual machine-centric relationships.
- Host Resources – Displays host-centric relationships.
- Datastore Resources – Displays datastore-centric relationships.
- vMotion Resources – Displays hosts available for vMotion migration.
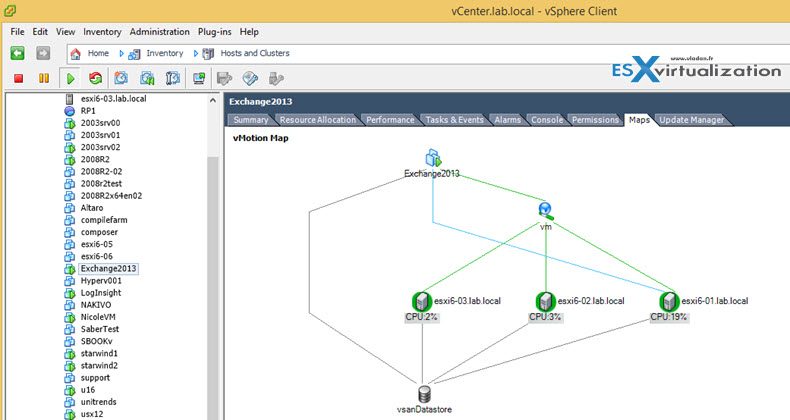
You can configure the maximum requested topology entities (helps for large environments) via vSphere client by going to the Client Menu > Edit > Client settings > Maps TAB
Identify the root cause of a DRS/HA cluster or migration issue based on troubleshooting information
Verify Fault Tolerance configuration
vSphere 6 has introduced New FT with up to 4vCPU support. However if virtual machine has only a single vCPU, however, you can use legacy FT instead, for backward compatibility. But, unless technically necessary, use of legacy FT is not recommended.
To use legacy Fault Tolerance, you must configure an advanced option for the virtual machine. After you complete this configuration, the legacy FT VM is different in some ways from other fault tolerant VMs.
Difference between Legacy FT (used in previous releases of vSphere) and FT (v6).
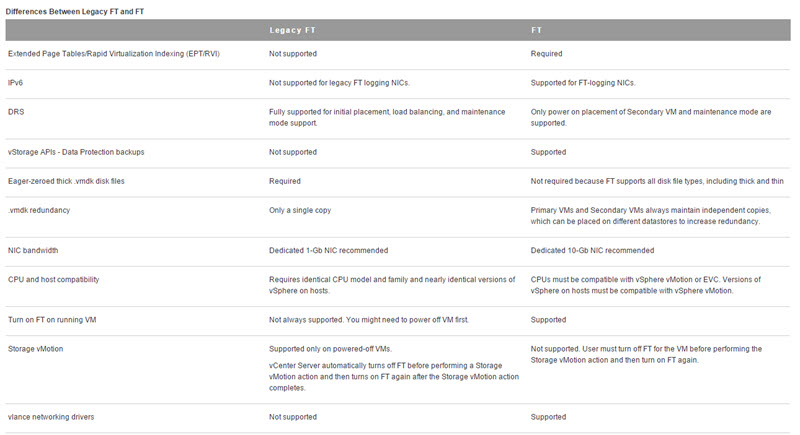
If you want/need to use legacy FT, check the requirements.
Identify Fault Tolerance requirements
Licensing – The number of vCPUs supported by a single fault tolerant VM is limited by the level of licensing that you have purchased for vSphere. Fault Tolerance is supported as follows:
- vSphere Standard and Enterprise. Allows up to 2 vCPUs
- vSphere Enterprise Plus. Allows up to 4 vCPUs
10 GbE Network – hard requirement for FT v6!
CPU Requirements – CPUs that are used in host machines for fault tolerant VMs must be compatible with vSphere vMotion or improved with Enhanced vMotion Compatibility. Also, CPUs that support Hardware MMU virtualization (Intel EPT or AMD RVI) are required. The following CPUs are supported.
- Intel Sandy Bridge or later. Avoton is not supported.
- AMD Bulldozer or later.
Possible Enforcing at the host level
Advanced settings:
das.maxftvmsperhost
The maximum number of fault tolerant VMs allowed on a host in the cluster. Both Primary VMs and Secondary VMs count toward this limit. The default value is 4.
das.maxftvcpusperhost
The maximum number of vCPUs aggregated across all fault tolerant VMs on a host. vCPUs from both Primary VMs and Secondary VMs count toward this limit. The default value is 8.
Tools
- vSphere Resource Management Guide
- vSphere Monitoring and Performance Guide
- vSphere Installation and Setup Guide
- vSphere Troubleshooting Guide
- vSphere Availability Guide
- vSphere Client / vSphere Web Client
Under the sVMotion heading you said:
Licensing – sVMotion is “Enterprise Plus” licensing…
From what I can tell Storage vMotion is supported by Standard, but SDRS requires Enterprise Plus. Is that what you meant?
http://www.vmware.com/files/pdf/vsphere_pricing.pdf
Absolutely right Josh. I must have been really tired while writing this… Thanks a lot. Corrected.
Under vMotion requirements, you state that Virtual Machines with RDM’s cannot be migrated through vMotion. This is not true: you can perform vMotion migrations of virtual machines with either physical or virtual compatibility mode Raw Device Mappings, and this has been the case for several versions (since at least vSphere 5). The statement about MSCS virtual machines not being able to migrate is true, and a lot of people draw the wrong conclusions: MSCS requires RDM’s (physical compatibility mode preferred). And these virtual machines can’t be migrated through vMotion. The reason though, is because MSCS requires SCSI Bus Sharing of the Quorum and Data disks, and it is the sharing that breaks vMotion, not the RDM.
Absolutely true. I don’t know why I stated it. The only thing with RDMs is to make sure that if (for virtual RDM) RDM pointer files are not stored on a local datastore otherwise the remote host (to which you want to vMotion) will not see the pointer, and so throws an error.
Thanks again for you comment Thomas. The post will get corrected.