
VMware VCP6-DCV certification exam is kind of holy grail as it's an exam you can't fake. You have to know your stuff. Many folks also need to re-certify after expiring their VCP 4 or VCP 5. For current VCP5-DCV holders it's also possible to pass the VCP6-DCV delta exam, which has 45 questions only. Today's topc? VCP6-DCV Objective 9.1 – Configure Advanced vSphere HA Features.
Those study blog posts are covering topics and objectives from the blueprint from VCP 6 page and are here to help out with studying towards the VMware Certification Exam VCP6-DCV (Datacenter Virtualization). This exam validates you have the skills required to successfully install, deploy, scale and manage VMware vSphere 6.
vSphere Knowledge
- Explain Advanced vSphere HA settings
- Enable/Disable Advanced vSphere HA settings
- Explain how vSphere HA interprets heartbeats
- Interpret and correct errors during conversion
- Identify virtual machine override priorities
- Identify Virtual Machine Component Protection (VMCP) settings
—————————————————————————————————–
Explain Advanced vSphere HA settings
vSphere HA Advanced Options do not need to be changed in most environments.The HA advanced settings are applied at the cluster level.
There is a very good VMware knowledge base article at https://kb.vmware.com/kb/2033250, which is based on vSphere 5.x but still relevant for vSphere 6.
From vSphere 6.0 documentation center:
- das.isolationaddress[…] – Sets the address to ping to determine if a host is isolated from the network. This address is pinged only when heartbeats are not received from any other host in the cluster. If not specified, the default gateway of the management network is used. This default gateway has to be a reliable address that is available, so that the host can determine if it is isolated from the network. You can specify multiple isolation addresses (up to 10) for the cluster: das.isolationaddressX, where X = 0-9. Typically you should specify one per management network. Specifying too many addresses makes isolation detection take too long.
- das.usedefaultisolationaddress – By default, vSphere HA uses the default gateway of the console network as an isolation address. This option specifies whether or not this default is used (true|false).
- das.isolationshutdowntimeout – The period of time the system waits for a virtual machine to shut down before powering it off. This only applies if the host's isolation response is Shut down VM. Default value is 300 seconds.
- das.slotmeminmb – Defines the maximum bound on the memory slot size. If this option is used, the slot size is the smaller of this value or the maximum memory reservation plus memory overhead of any powered-on virtual machine in the cluster.
- das.slotcpuinmhz – Defines the maximum bound on the CPU slot size. If this option is used, the slot size is the smaller of this value or the maximum CPU reservation of any powered-on virtual machine in the cluster.
- das.vmmemoryminmb – Defines the default memory resource value assigned to a virtual machine if its memory reservation is not specified or zero. This is used for the Host Failures Cluster Tolerates admission control policy. If no value is specified, the default is 0 MB.
- das.vmcpuminmhz – Defines the default CPU resource value assigned to a virtual machine if its CPU reservation is not specified or zero. This is used for the Host Failures Cluster Tolerates admission control policy. If no value is specified, the default is 32MHz.
- das.iostatsinterval – Changes the default I/O stats interval for VM Monitoring sensitivity. The default is 120 (seconds). Can be set to any value greater than, or equal to 0. Setting to 0 disables the check. Note: Values of less than 50 are not recommended since smaller values can result in vSphere HA unexpectedly resetting a virtual machine.
- das.ignoreinsufficienthbdatastore – Disables configuration issues created if the host does not have sufficient heartbeat datastores for vSphere HA. Default value is false.
- das.heartbeatdsperhost – Changes the number of heartbeat datastores required. Valid values can range from 2-5 and the default is 2.
- fdm.isolationpolicydelaysec – The number of seconds system waits before executing the isolation policy once it is determined that a host is isolated. The minimum value is 30. If set to a value less than 30, the delay will be 30 seconds.
- das.respectvmvmantiaffinityrules – Determines if vSphere HA enforces VM-VM anti-affinity rules. Default value is “false”, whereby the rules are not enforced. Can also be set to “true” and rules are enforced (even if vSphere DRS is not enabled). In this case, vSphere HA does not fail over a virtual machine if doing so violates a rule, but it issues an event reporting there are insufficient resources to perform the failover.
- das.maxresets – The maximum number of reset attempts made by VMCP. If a reset operation on a virtual machine affected by an APD situation fails, VMCP retries the reset this many times before giving up
- das.maxterminates – The maximum number of retries made by VMCP for virtual machine termination.
- das.terminateretryintervalsec – If VMCP fails to terminate a virtual machine, this is the number of seconds the system waits before it retries a terminate attempt
- das.config.fdm.reportfailoverfailevent – When set to 1, enables generation of a detailed per-VM event when an attempt by vSphere HA to restart a virtual machine is unsuccessful. Default value is 0. In versions earlier than vSphere 6.0, this event is generated by default.
- vpxd.das.completemetadataupdateintervalsec – The period of time (seconds) after a VM-Host affinity rule is set during which vSphere HA can restart a VM in a DRS-disabled cluster, overriding the rule. Default value is 300 seconds.
- das.config.fdm.memreservationmb – By default vSphere HA agents run with a configured memory limit of 250 MB. A host might not allow this reservation if it runs out of reservable capacity. You can use this advanced option to lower the memory limit to avoid this issue. Only integers greater than 100, which is the minimum value, can be specified. Conversely, to prevent problems during master agent elections in a large cluster (containing 6,000 to 8,000 VMs) you should raise this limit to 325 MB.
Note : Once one of the options is changed, for all hosts in the cluster you must run the Reconfigure HA task. Also, when a new host is added to the cluster or an existing host is rebooted, this task should be performed on those hosts in order to update this memory setting.
Enable/Disable Advanced vSphere HA settings
If you change the value of any of the following advanced options, you must disable and then re-enable vSphere HA before your changes take effect. You can use both clients (Windows C# client or vSphere Web client). You enable/disable always at the cluster level
Using the vSphere Web Client
- Log in to VMware vSphere Web Client.
- Click Home > vCenter > Clusters.
- Under Object click on the cluster you want to modify.
- Click Manage.
- Click vSphere HA.
- Click Edit.
- Click Advanced Options.
- Click Add and enter in Option and Value fields as appropriate (see below).
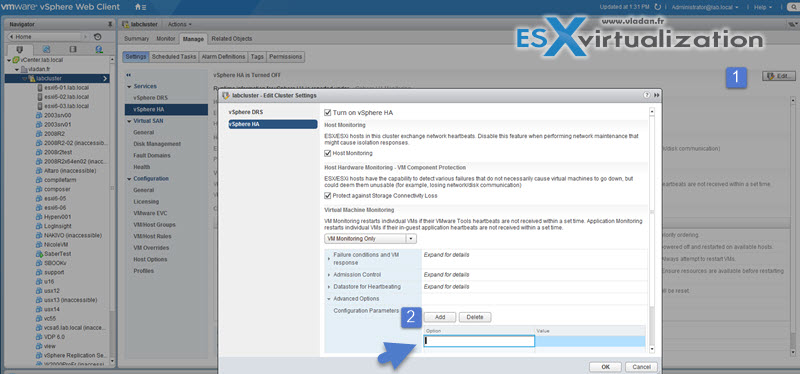
- Deselect Turn ON vSphere HA.
- Click OK.
- Wait for HA to unconfigure, click Edit and check Turn ON vSphere HA.
- Click OK and wait for the cluster to reconfigure.
To get back to the defaults:
remove fdm.cfg file on each hosts in the cluster OR reset the values to defaults on each host in the cluster.
Explain how vSphere HA interprets heartbeats
When configuring VMware High Availability (HA) cluster, you have the possibility to check as a secondary communication channel a datastore (or several ones), during the configuration wizard. VMware Datastore Hearbeating provides an additional option for determining if host is in failed state or not.
In case the Master cannot communicate with a slave (don’t receives the heartbeat), but the heartbeat datastore answers, the server is still working. So if that’s the case, the host is partitioned from the network, or isolated. The Datastore heartbeat function helps greatly to determine the difference between host which failed and host that has just been isolated from others.
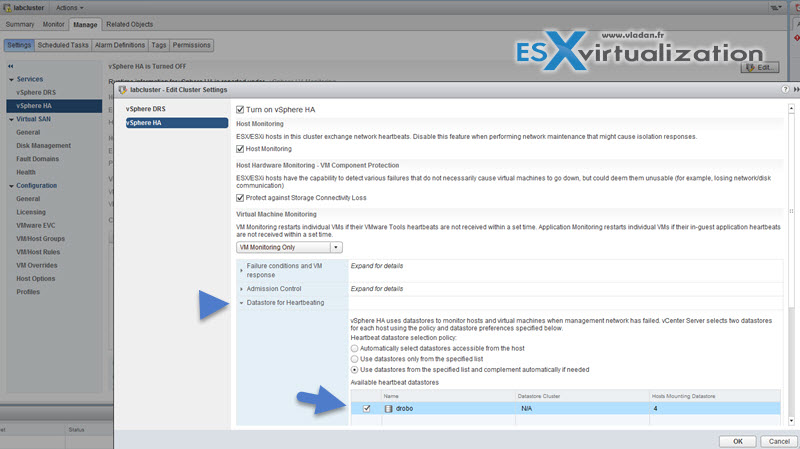
The Purpose of the .vSphere-HA folder
This folder resides on shared datastore which is used as a secondary communication channel in HA architecture. This folder has several files inside, and everyone of them has different rôle (I don't think that's the required topic of the exam, but it's interesting to know in case you browse your shared datastore and see the folder inside):
- host-xxx-hb files – those files are for the heartbeat datastore. The heartbeat mechanism uses the part of the VMFS volume for regular updates. Each host in cluster has it’s own file like this in the .vSphere-HA folder.
- protected list file – when you open this file, you’ll see a list of VMs protected by a HA. The master host uses this file for storing the inventory and the state of each VM.
- host-xxx-poweron files – this files role’s is to track the running VMs for each host of the cluster. The file is read by the master host which will know if a slave host is isolated from the network. Slave hosts uses this poweron file to tell the master host “hey, I’m isolated”. The content of this file reveals that there can be two states: zero or one. Zero = not isolated and One = isolated. If the slave host is isolated, master host informs vCenter.
The .vSphere HA folder is created only on datastores that are used for the datastore heartbeating. You shouldn’t delete or modify those files. The space used is minimum, depending on the VMFS version used and number of hosts that uses this datastore for heartbeating. It can be maximum about 3 Gb for on VMFS 3 and 2Mb on VMFS 5 (maximm and typical usage). The overhead isn’t big either.
Limitations of Datastore hearbeating:
- No VSAN support
Interpret and correct errors during conversion
This chapter is concerning VMware converter. It's been recently update to version 6.
- Troubleshooting when vCenter Converter fails to complete a conversion of a physical or virtual machine.
- Testing port connectivity with Telnet (1003487)
- Best practices for using and troubleshooting VMware Converter (1004588)
- Troubleshooting a virtual machine converted with VMware Converter that fails to boot with the error: STOP 0x0000007B INACCESSIBLE_BOOT_DEVICE (1006295)
- Required VMware vCenter Converter 4.x/5.x ports (1010056)
- Collecting diagnostic information for VMware Converter (1010633)
- TCP and UDP Ports required to access VMware vCenter Server, VMware ESXi and ESX hosts, and other network components (1012382)
- VMware vCenter Converter is unable to see the disks when converting Windows operating systems (1016992)
- vCenter Standalone Converter errors when an ESXi 5.x host is selected as a destination: The access to the host resource settings is restricted. Use the management server as a destination (2012310)
Tips and Tricks from ESX Virtualization and Vladan… -:)
- How-to disable SSL in VMware vCenter Converter Standalone to speed up P2V conversions
- How-to Reduce VMDK size: VMware Converter
- How to use VMware Converter to Synchronize changes when P2V (or V2V)
- VMware Converter Best Practices
Identify virtual machine override priorities
You can customize settings for each VM in the cluster for VM restart priority, VMCP (see bellow), Host isolation response or VM monitoring.
Where?
In the vSphere Web Client, browse to the vSphere HA cluster > Manage tab > Settings > Under Settings, select VM Overrides and click Add > Click the + button to select virtual machines to which to apply the overrides > OK.
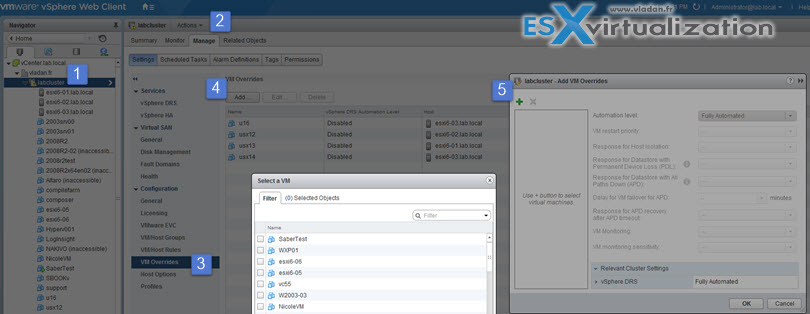
If applied on the per-VM level, the settings now have more priority than the cluster settings and so they are different on every other VMs. At the same time you can apply DRS rules there (you can see on the image above I have some VMs which are not balanced automatically by DRS when Fully automated DRS is configured.
Identify Virtual Machine Component Protection (VMCP) settings
HA was further enhanced with a function related to shared storage and it’s called VM Component Protection (VMCP).
When VMCP is enabled, vSphere can detect datastore accessibility failures, APD (All paths down) or PDL (Permannent device lost), and then recover affected virtual machines by restarting them on other host in the cluster which is not affected by this datastore failure. VMCP allows the admin to determine the response that vSphere HA will make. It can be simple alarm only or it can be the VM restart on other host. The latter one is perhaps what we’re looking for. Let’s HA handle this for us….
Limitations:
- VMCP does not support vSphere Fault Tolerance. If VMCP is enabled for a cluster using Fault Tolerance, the affected FT virtual machines will automatically receive overrides that disable VMCP.
- No VSAN support (if VMDKs are located on VSAN then they're not protected by VMCP).
- No VVOLs support (same here)
- No RDM support (same here)
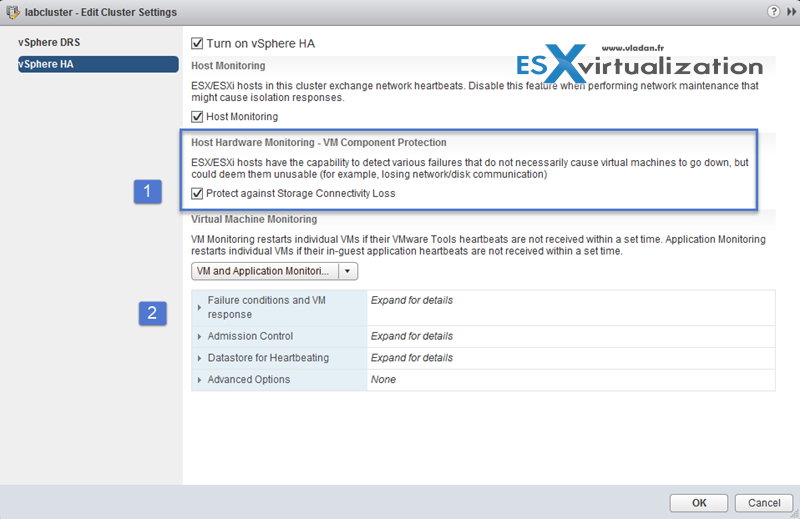
How to enable?
At the cluster level. vSphere Client Select Hosts and clusters > Manage > vSphere HA > Edit > Protect against Storage Connectivity Loss.
You must configure it on two places
- Check the box “Protect against Storage Connectivity Loss”
- Expand the “Failure conditions and VM response”
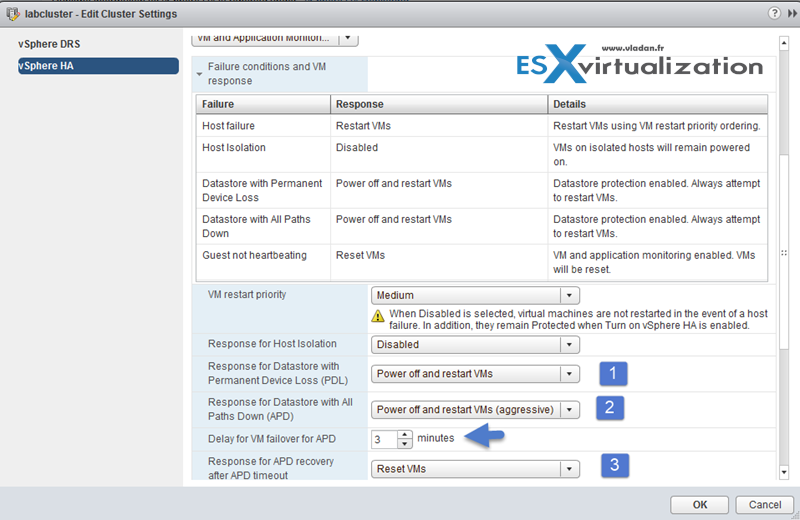
The second condition allows to specify what happens. There you have to specify 3 options:
By default it does not restart the VM on another host so it’s important to do it.
There you’ll see to options which you need to configure:
- Response for Datastore with Permanent Device Lost (PDL)
- Response for Datastore with All Path down (APD) – with this one you have two choses. To be more conservative or more aggressive. Basically it means to wait longer (or shorter) time in case the problem is resolved. As I mentioned at the beginning of my post, APD can be resolved (can be temporary outage) but PDL can’t.
- Response for APD recovery after APD timeout – change it to “reset VMs” as by default its disabled.
All paths down (APD) – vSphere will restart the VM after user-configured timeout only if there is enough capacity.
Action? Restart on a healthy host. Reset a VM if APD clears after APD timeout.
Permannent device lost (PDL) – vSphere suppose that the device won’t show up back again and is “lost” due to hardware failure.
Action? Terminate VM immediately and restart on a healthy host.
If the Host Monitoring or VM Restart Priority settings are disabled, VMCP cannot perform virtual machine restarts.
The VMCP settings has to be changed from their default values as by default the Response for APD recovery after APD is disabled.
You can check settings at the cluster level, but also via the VM’s properties at the VM level by selecting the VM through vSphere Web client.
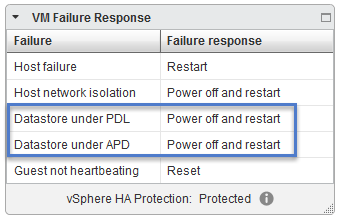
Those fine-grain options allows to react on unpredictable APD and PDL signals when using shared storage within your environment and give you significant insurance in case of connectivity problems to your shared storage.
Links and Tools
- vSphere Installation and Setup Guide
- vSphere Availability Guide
- What’s New in the VMware vSphere® 6.0 Platform
- vSphere Administration with the vSphere Client Guide
- vSphere Client / vSphere Web Client
Do you truly mean “maximum about 3 Gb for on VMFS 3 and 2Mb on VMFS 5” or should both be Mb? That seems like a significant size difference.
Slightly edited to make it more clear, but basically it’s like that. VMFS 5 it’s 2Mb only…. Check this: https://pubs.vmware.com/vsphere-60/index.jsp#com.vmware.vsphere.avail.doc/GUID-0502B198-F5F7-4101-969C-C5B6F364C678.html?resultof=%2522%2564%2561%2574%2561%2573%2574%256f%2572%2565%2522%2520%2522%2564%2561%2574%2561%2573%2574%256f%2572%2522%2520
so thanks
i have a question about vmcp and ADP
i know host will be send I/o 140s to storage array after passed if not respond will be continue send I/O request for 3min there is other option :
Response for APD recovery after APD timeout can say me exactly what will be do this option if i select disable or restart ?
what happen if i set that option on disable ?
BR