
Today we'll detail another objective towards VCP-DCV 2019 Certification – Objective 1.6 – Describe and differentiate among vSphere, HA, DRS, and SDRS functionality. We won't be able to cover everything about those technologies in a single post – make sure to read the PDF documentation to know everything inside out for the exam. The VMware Exam blueprint has 41 chapters (Objectives). VCP-DCV 2019 certification is the latest certification based on vSphere 6.7.
The VCP-DCV 2019 certification will be based on 2V0-21.19 exam number and it will have 70 questions with a duration of 115 minutes. The passing score is 300. Nothing really new for those who are not new to VMware certification process.
However, VMware changed the rules of re-certification recently. Our Post: VMware Certification Changes in 2019 has the details. No mandatory recertification after 2 years. Older certification holders (up to VCP5) can pass the new exam without a mandatory course, only recommended courses are listed).
The certification's name is “The VCP-DCV 2019 certification“. It is a new certification for 2019 focusing on installation, configuration, and management of VMware vSphere 6.7.
To become VCP-DCV 2019 certified you have 3 different choices of exam:
- Professional vSphere 6.7 Exam 2019
- VMware Certified Professional 6.5 – Data Center Virtualization exam (our VCP6.5-DCV Study Guide Page which is complete)
- VMware Certified Professional 6.5 – Data Center Virtualization Delta exam
Note: You must be VCP5, or VCP6. If, not, you must “sit” a class and you have no “Delta” exam option.
The current exam blueprint: (Original PDF Online at VMware is here 2V0-21.19).
This guide is available as Free PDF!
Free Download at Nakivo – VCP6.7-DCV Study Guide.

VCP-DCV 2019 Study Guide
Objective 1.6 – Describe and differentiate among vSphere, HA, DRS, and SDRS functionality
There are very little guidelines about what should be covered in this chapter. We don't have any sub-chapter topic we could stick to, so we'll just see what we think that should be covered and what we can put into this post without exploding the word count.
Note: You should check our VCP6.5-DCV study guide which has had a better internal structure in each objective and the technology between vSphere 6.5 and 6.7 did not change that much.
VMware vSphere
Comparing ESXi and vSphere? Possibly. VMware ESXi = Standalone host. Many ESXi hosts need a central management = vCenter server. vCenter and ESXi hosts are basically the two principal components which form a VMware vSphere Infrastructure.
VMware vSphere is a commercial name for the whole VMware Suite. vCenter itself is just one part of the licensing puzzle. You need to have a license for each of your connected ESXi hosts in order to manage them from a single central location. Those licensing has basically 3 different flavors (Standard, Enterprise, vSphere with Operations Management Enterprise, Platinum) and it counts per physical CPU.
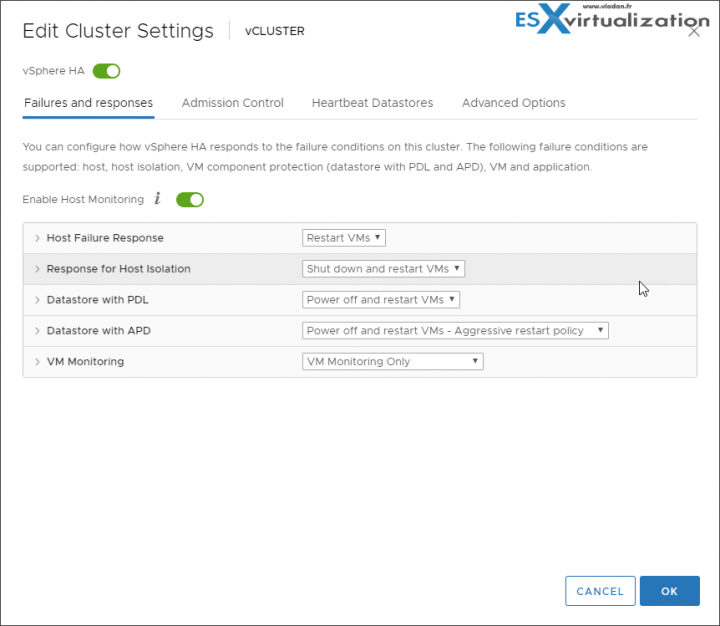
VMware High Availability (HA)
VMware HA protects against host or storage failures. If there is an unplanned hardware failure, vSphere High Availability (HA) can restart automatically VMs which failed when the host failed. Those VMs are automatically restarted on other hosts which are part of VMware cluster.
There is small downtime during which the system figures out what the host has failed and which are the hosts that are able to start the failed VMs. Those hosts must have enough available capacity in terms of memory or CPU. Once this automatic decision is taken, the VM boots up. The whole process is completely automatic and acts without the admin’s intervention.
A single host within vSphere HA cluster is automatically elected as the master host. The master host communicates with vCenter Server and monitors the state of all protected virtual machines
and of the slave hosts.
When you add a host to a vSphere HA cluster, an agent is uploaded to the host and configured to communicate with other agents in the cluster.
The master host and it's responsibilities:
- To Monitor the state of slave hosts. If there is a slave host which fails or unavailable, the master host knows which VMs needs to be restarted on other hosts.
- The master host also monitors the power state of all protected VMs. If one VM fails, then the master host makes sure that this particular VM will be restarted and monitors the progress. The master also knows the resources available and so, it can make a decision where to restart that VM (on which host).
- Master host manages a list of cluster hosts and protected VMs.
The slave hosts provide secondary, passive tasks, where they report on the state of VMs which are running on the slave hosts, updates the master with its availability and its resources.
The master host is able to “orchestrate” restarts of protected VMs.
If the master fails. In that case, there is a re-ellection process and the host which has access to the greatest number of datastores is elected as a master. It’s because the secondary communication channel is through datastores. There are other considerations for a Slave to become elected as a Master as well.
HA can protect you against the host or network failure. In the case that the host gets isolated, the response to this event can be configured differently so the VM can stay up and running (instead of killed and restarted elsewhere). But let’s explore this for more details.
In a vSphere HA cluster, three types of host failures can be detected:
- Failure – When a host stops functioning.
- Isolation – When a host becomes network isolated.
- Partition – When a host loses network connectivity with the master host (A “Master” host is only one within the cluster, and it’s the one who is responsible for monitoring the “slave” hosts within the cluster).
The secondary channel through datastores is known as a Heartbeat Datastores. But this secondary network is not used in normal situations, only in case the primary network goes down. This secondary channel permits the Master to be aware of all Slave hosts and also the VMs running on those hosts. The Heartbeat datastores can also determine if the host became isolated or network partitioned. The secondary channel can determine if the host is failed (PSOD) or if it’s just isolated.
VM Restart Priority
Quote:
VM restart priority determines the relative order in which virtual machines are allocated resources after a host failure. Such virtual machines are assigned to hosts with unreserved capacity, with the highest priority virtual machines placed first and continuing to those with lower priority until all virtual machines have been placed or no more cluster capacity is available to meet the reservations or memory overhead of the virtual machines.
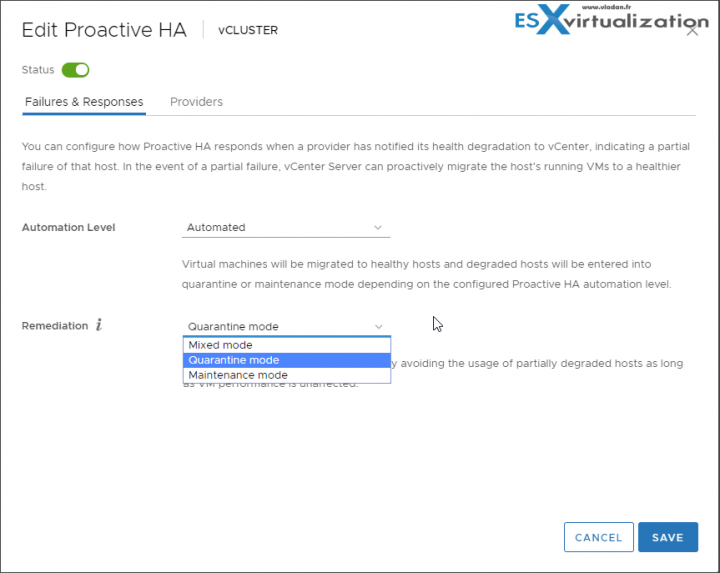
Proactive HA
If you have a component failure, which affects the redundancy. No failure yet. You can configure how Proactive HA responds when a provider has notified its health degradation to vCenter, indicating a partial failure of that host. n this case, the VMs residing on that host can be evacuated to other hosts and the host where is the failure is placed in Quarantine mode or Maintenance Mode.
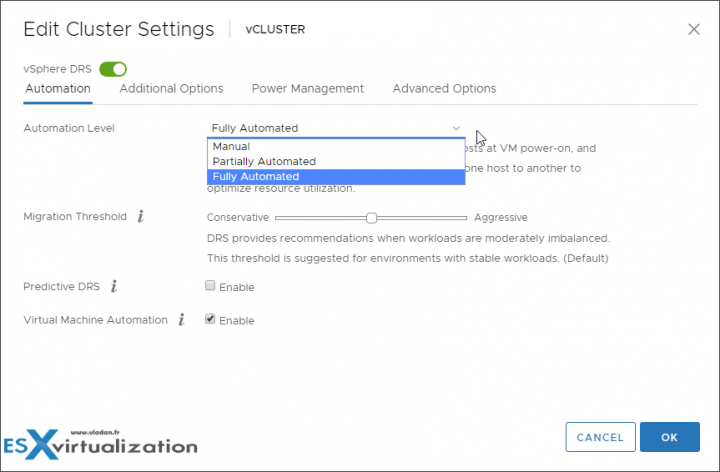
VMware Distributed Resource Scheduler (DRS)
VMware vSphere Distributed Resource Scheduler (DRS) is a resource scheduler. It monitors and it can react to changes in VM workloads. The system can migrate VMs to other hosts in order to distribute the load.
DRS automatically places virtual machines onto hosts at VM power-on, and virtual machines are automatically migrated from one host to another to optimize resource utilization.
Started in VMware vSphere 6.5, vSphere DRS can predictively migrate workloads based on existing patterns in those workloads.
Note: If you're using VMware FT, then you should know that vSphere DRS do not load balance FT protected VMs (unless they're using Legacy FT managed by vCenter server 6.0). As such you might end up with an FT VMs being unevenly distributed across your cluster.
Screenshot from VMware documentation (“vSphere ESXi vCenter Server 6.7 resource management guide” – Page 69):

vSphere DRS Requirements:
- Minimum 3 hosts and activated DRS in the cluster.
- VMware vCenter Server
- vMotion network enabled on all hosts within your cluster
- Enterprise Plus licensing
- Shared Storage connected to all hosts within the cluster.
- If using predictive DRS, you will need vRealize Operations (vROPs). – Note you must also configure Predictive DRS in a version of vRealize Operations that supports this feature.
vSphere HA and DRS – Better together – If you're using HA with DRS you basically getting automatic failover with load balancing. You get your cluster more balanced after HA moved VMs to a different host.
We have just scratched a surface on DRS… Read the doc to learn more.
VMware Storage DRS
A datastore cluster is a collection of datastores with shared resources and a shared management interface. When you create a datastore cluster, you can use vSphere Storage DRS to manage storage resources.
Storage DRS allows you to manage the aggregated resources of a datastore cluster, which means that you can balance a space and I/O load between different datastores within a datastore cluster. Also, SDRS manages the initial placement of virtual disks based on space and I/O workload. Today’s post is entitled – What is VMware Storage DRS (SDRS)?
What is an initial placement? The initial placement is a process when you select a datastore within datastore cluster where you want to place a virtual machine disk and the system will propose you the best possible place. SDRS and initial placement are happening when for example you create a new virtual machine (VM) or clone VM.
This also happens when a virtual machine disk (VMDK) is migrated to another datastore cluster, or when you add a disk to an existing VM.
SDRS enables or disables all of these components (I/O, initial placement, and space load balancing) at once. If necessary, you can disable I/O-related functions of Storage DRS independently of space balancing functions.
There is a manual mode which shows only recommendations, and there is automation mode which does move VMDKs around. SDRS recommend the placements of VM(s), their VMDKs, from which datastore (source) to which datastore (destination) and also it shows you what is the reason for the recommendation. It can be that the source datastore is running out of space or anti-affinity rules are violated or the datastore is entering maintenance mode.
Datastore clusters must contain similar or interchangeable datastores. A datastore cluster can contain a mix of datastores with different sizes and I/O capacities, and can be from different arrays and vendors.
Where to enable SDRS?
Right-click the data center object and select New Datastore Cluster.
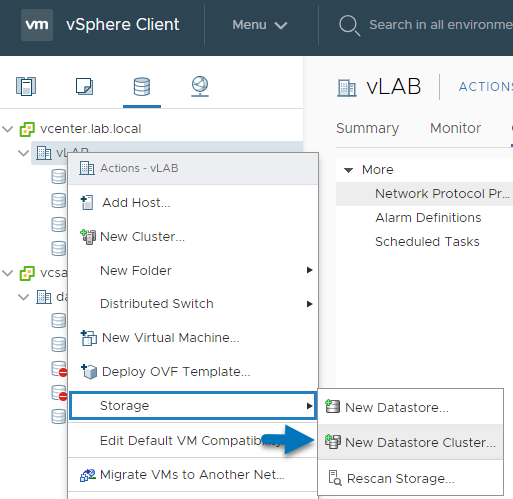
A wizard will walk you through…
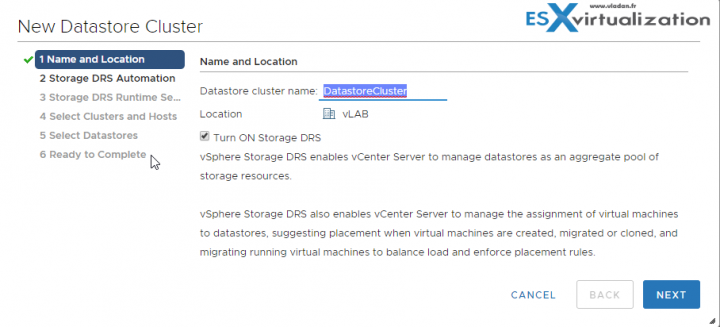
Once finished, you can come back to modify those settings. Simply select the datastore cluster > Edit.

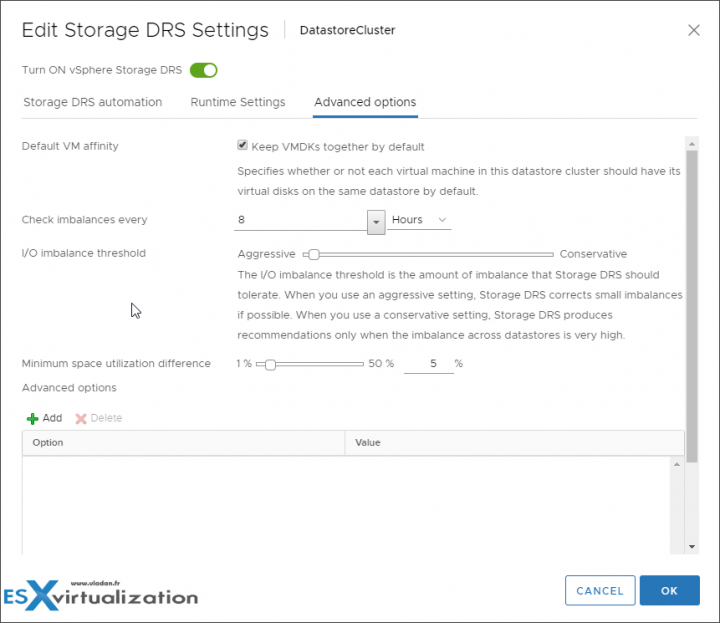
Note: that by default “Keep VMDKs together” by default is selected. It specifies whether or not each virtual machine in this datastore cluster should have its virtual disks on the same datastore by default.
What are VMware Storage DRS Requirements?
- The use similar or interchangeable datastores for a datastore cluster is allowed.
- There can be a mix of datastores with different sizes and I/O capacities and can be from different arrays and vendors.
- You cannot use NFS and VMFS within the same datastore cluster.
- There cannot be used – Replicated datastores with non-replicated datastores in the same Storage-DRS-enabled datastore cluster.
- Datastores which are shared across multiple datacenters are not allowed.
- All hosts must be at least ESXi 5.0
- Best practice – do not include datastores with hardware acceleration enabled with datastores without hardware acceleration enabled.
Advanced Options
The I/O imbalance threshold is the amount of imbalance that Storage DRS should tolerate. When you use an aggressive setting, Storage DRS corrects small imbalances if possible. When you use a conservative setting, Storage DRS produces recommendations only when the imbalance across datastores is very high.
At the end of each chapter, I have the feeling that I have just scratched the surface. That there is more to learn and more to know for the exam. I hope you have the same feeling and that you continue to study more. Not just relying on our study guide.
Check the VCP6.7-DCV Study Guide Page for all objectives and the whole documentation set.
Also from ESX Virtualization
- VCP6.7-DCV Objective 7.5 – Configure role-based user management
- What is VMware vSphere Update Manager?
- What is VMware DRS (Distributed Resource Scheduler)?
- What Is Erasure Coding?
Stay tuned through RSS, and social media channels (Twitter, FB, YouTube)