
Imagine you have the possibility to plugin a single (or multiple) SSDs to each of your host of you cluster running VMware vSphere, and create a very fast redundant storage tier based on flash. In addition, no existing network or storage changes are necessary. Pure fiction? Not really. PernixData is new startup company, which works on a product called FVP. The product (In public beta) offers superior advantages over traditional flash based software solution which offers read cache or at most write-through caching only.

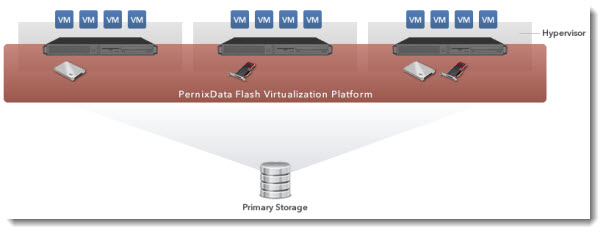
Managed through vCenter as any other storage plugin, the product does not rely on agents in VMs and it's not a virtual appliance with traditional overhead either. The core of the FVP sits at the hypervisor level and manages the reads and writes of data between VM and the Flash Storage Pool. The installation process can even leverage vSphere Update Manager to push the VIB to each of the hypervizor which is part of the cluster. All existing enterprise class features of vSphere like DRS, HA and Storage DRS are not disrupted, but fully supported with FVP. That's very important, as many businesses rely on those features for their DR scenarios.
What's the Key points of FVP by PernixData?
Write-Back Caching – write back caching allows for the writes to be acknowledged when they were written to the SSD device. ( write through caching offloads the reads only). The product is further configurable whether the changes to the data are written to SSD and later to the slower storage tier.
Agent Less Solution – no agents on the VMs as the product is part of the hypevizor's module. So there isn't any virtual appliance (VSA) to deploy.
Pool of Flash Tier – the local SSD drives or PCI-E Flash cards are pooled together to create an unified storage flash pool. This pool is redundant and when running in Write Back mode data stored on flash can be replicated to at least another server.
User Experience: The PernixData UI is easy to use and has rich charts for performance analysis. Also, all virtual machine operations such as vMotion, DRS, HA, snapshots, suspend/resume etc. work seamlessly and there is no need to change any operational workflows because of FVP.
I've asked few questions the folks that working at PernixData and they replied with a pleasure with some more deep details. I asked Bala Narasimhan and Andy Daniel, both working for PernixData.
Question 1: One of the first questions that might interest ESX Virtualization readers is how the redundancy of data is assured and maintained in case of server (or the flash card) failure. I imagine that the data are replicated at the block level between several servers. But are there any details that you can tell us more about?
PernixData: Failure handling is a key part of FVP design. With FVP, VMs continue to run in the event of failures For example, when a flash device fails VMs continue to operate unscathed. In Write Back mode, FVP uses replication in order to achieve failure handling. We allow users to choose how many replicas they want across the cluster on a per VM basis. This is important because, depending on the application, a VM may or may not be sensitive to failure handling. If you are running an OLTP database within a VM then you are definitely sensitive to failure handling and should choose 1 or 2 replicas for your data. However, if it is a ‘test & dev’ VM you may not care as much and so can choose 0 replicas if you want to. Again, we have focused heavily on the user experience and empowering the user to make the right choices for their environment.
Question 2: We certainly will see the increase in the performance, that's the goal of the FVP solution. Will the solution benefit also smaller businesses which uses 1Gb at the storage network? As I understand that the data must travel via the storage network to assume the redundancy.
 PernixData: I’d like to point out that when a VM is run in Write Through mode there is no need for replication. It is when one configures a VM in Write Back mode that FVP uses replication for failure handling. As a result FVP will definitely benefit the environments you refer to. The exact improvements are, of course, a function of the workload. But remember that we are talking about top-of-the-rack switching latencies and less about queuing delays with FVP and that makes a big difference!
PernixData: I’d like to point out that when a VM is run in Write Through mode there is no need for replication. It is when one configures a VM in Write Back mode that FVP uses replication for failure handling. As a result FVP will definitely benefit the environments you refer to. The exact improvements are, of course, a function of the workload. But remember that we are talking about top-of-the-rack switching latencies and less about queuing delays with FVP and that makes a big difference!
Question 3: This is the first Distributed flash storage solution that allows the administrator to leverage place in the existing servers (organized in clusters) by plugging in some SATA (or PCI-Express) SSDs to accelerate without using VSA. How the idea was born?
PernixData: FVP was born out of the realization that scale-out storage should be available to everyone in the most effortless way possible. PernixData’s CTO and co-founder, Satyam Vaghani, is a thought leader in the storage industry. As you may know Satyam was a Principal Engineer for storage at VMware and had a role to play in most storage related innovation that came out of VMware, the earliest and most famous one being VMFS. This product carries his signature.
It was also clear to the founders that unlocking the true potential of server-side flash required leveraging it as an enterprise-class ‘Data in motion’ tier that solves the IOPS problem much more efficiently in front of any storage system that provides ‘Data at rest’ capacity.
Continue reading about Flash Virtualization Platform (FVP) on next page ->
Nice article. Repplied to all my questions 🙂
Thanks.