
In this post, we'll try to describe HA solutions for vSphere. I think here VMware wants us to give an overview of High availability and its usage within the enterprise, describe how this process works and what's happens when HA event gets triggered. This post's name is VCP6.7-DCV Objective 2.2 – Describe HA solutions for vSphere and it is another step towards the VCP-DCV Study Guide we're preparing. If you're thinking of passing a VCP exam, stay tuned as right now we're about halfway through all of the 41 topics present on the official VMware blueprint.
However, there might be another point which can apply to this chapter, and it is the vCenter Server appliance high availability (VCSA HA) as without vCenter it's not possible to configure HA, but also other cluster functions. So we'll cover briefly this functionality of VCSA as well.
Otherwise, vSphere HA is fully automatic, no admin or user interaction is necessary. vCenter is used only for configuration options. HA agents communicate without the need of having vCenter active or online.
VMware High Availability (HA) has been launched with the launch of vCenter Server In 2003. The same year, other features such as VMotion, and Virtual SMP technology. The 64-bit support came in 2004.
When a hardware problem occurs, it would be great to have some kind of mechanism that the VM can start on another host, right? And that’s exactly what VMware HA is all about. It provides an automatic start of VMs which were running on the failed host. Those VMs are started in sequences.
This guide is available as Free PDF!
Free Download at Nakivo – VCP6.7-DCV Study Guide.

VCP-DCV 2019 Study Guide
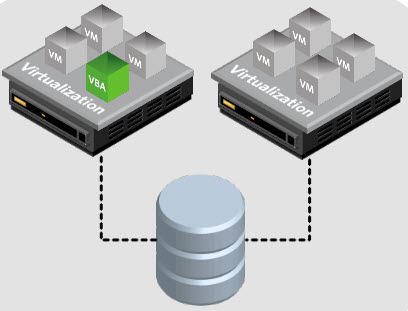
Let’s assume we have two hosts and one external storage (this can be a SAN/NAS device) where those servers are connected to and you can see the shared storage from both servers at the same time.
The servers see the shared storage, access it at the same time, and read or write at the same time to the shared storage. (not write to individual VMs at the same time, because each VM uses a locking mechanism. A long time ago, VMware has invented at their beginning a clustered storage system called VMFS which allows several servers to read and write to the shared storage at the same time.
So, we have our VM running on Server 1, connected to shared storage. And we also have Server 2 which is connected to that shared storage. You can see a simple overview on the image below…
How VMware HA Works?
Hosts in the cluster are monitored and in the event of a failure, the virtual machines on a failed host are restarted on alternate hosts.
A minimal number of hosts within a cluster is two. The VM which runs on the left (on our picture) will be able to be restarted automatically by VMware HA on the host which is on the right. All the files which the VM is composed, such as virtual disks (VMDK), a configuration file (VMX) and others stay located on the shared storage. Those files do not move anywhere.
The only thing which is happening is that after the host on the left crashed or had a hardware problem, the VM is started automatically on the host which is on the right. (it’s very simplified as explication though…)
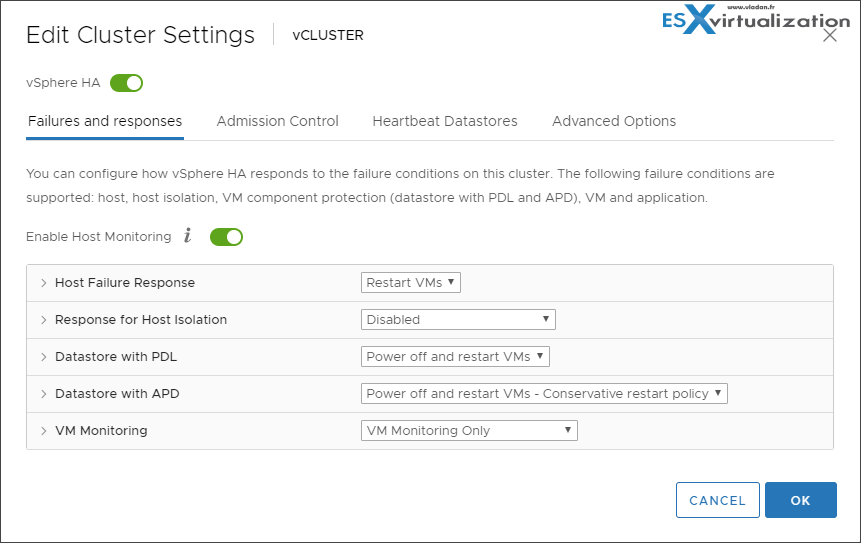
Before you create a vSphere HA cluster, you should know how vSphere HA identifies host failures and isolation and how it responds to these situations. All hosts which are part of the HA cluster are monitored and in the case of a failure, the VMs on a failed host are restarted on surviving hosts within the cluster. The goals are to have more than 2 hosts so the load can spread through the whole cluster and that the VMs which will start on those hosts does not suffer from underperformance.
HA can protect you against the host or network failure. In the case that the host gets isolated, the response to this event can be configured differently so the VM can stay up and running (instead of killed and restarted elsewhere). But let’s explore this for more details.
In a vSphere HA cluster, three types of host failures can be detected:
- Failure – When a host stops functioning.
- Isolation – When a host becomes network isolated.
- Partition – When a host loses network connectivity with the master host (A “Master” host is only one within the cluster, and it’s the one who is responsible for monitoring the “slave” hosts within the cluster).
A Master and Slave concept.
There is one master host in the cluster. The master host verifies if a host responds to ICMP pings sent to its management IP addresses. If a master host cannot communicate directly with the agent on a slave host, the slave host does not respond to ICMP pings. If the agent is not issuing heartbeats, it is viewed as failed.
Quote:
When you create a vSphere HA cluster, a single host is automatically elected as the master host. The master host communicates with vCenter Server and monitors the state of all protected virtual machines and of the slave hosts. Different types of host failures are possible, and the master host must detect and appropriately deal with the failure. The master host must distinguish between a failed host and one that is in a network partition or that has become network isolated. The master host uses network and datastore heartbeating to determine the type of failure.
The host’s virtual machines are restarted on alternate hosts. If such a slave host is exchanging heartbeats with a data store (yes, you can configure datastore heart beating as a secondary channel), the master host assumes that the slave host is in a network partition or is network isolated. So, the master host continues to monitor the host and its virtual machines.
Licensing costs for HA?
The lowest cost edition which allows you to stay protected by VMware HA is VMware Essentials Plus Term edition. It is a Time limited license. The same features as in “Essentials Plus” but for 12 months only. As such, the price is much lower than the Essentials Plus (normal).
VMware HA is configurable through an assistant, allowing you to specify several options. You’ll need a VMware vCenter server running in your environment.
vCenter server High Availability (VCSA HA)
In order to protect vCenter Server, VMware has introduced a concept of vCenter Server appliance High Availability (VCSA HA). It's only for a vCenter server running on VCSA, not on Windows.
A vCenter HA cluster consists of three vCenter Server Appliance instances. The first instance, initially used as the Active node, is cloned twice to a Passive node and to a Witness node. Together, the three nodes provide an active-passive failover solution. The Witness VM is a lightweight VM maintaining just the witness components.
Things that replicate between active and standby node:
- Database – The VCSA vPostgres database uses synchronous replication. It is a native vPostgres replication mechanism.
- Flat files – All configuration files, certificates, licensing info, etc. are replicated
Further reading from our VCP-DCV 2019 Study guide:
- VCP6.7-DCV Objective 1.9 – Describe the purpose of cluster and the features it provides
- VCP6.7-DCV Objective 1.6 – Describe and differentiate among vSphere, HA, DRS, and SDRS functionality
We follow VMware blueprint and all topics you can find on our VCP-DCV 2019 Study Guide page. The work in progress page gets updated almost daily so stay tuned.
Do not rely on our guide ONLY. Use other resources, your home lab, and, also an official VMware documentation.
More posts from ESX Virtualization:
- How To Login Into VMware vCenter Server Appliance (VCSA) Management page
- What is The Difference between VMware vSphere, ESXi and vCenter
- How to Configure VMware High Availability (HA) Cluster
- VCP6-DCV Objective 7.5 – Troubleshoot HA and DRS Configurations and Fault Tolerance
- VMware DRS Entitlement Viewer – Free Tool
- VCP6.7-DCV Objective 4.6 – Deploy and configure VMware vCenter Server Appliance (VCSA)
- How To Reset ESXi Root Password via Microsoft AD
Stay tuned through RSS, and social media channels (Twitter, FB, YouTube)